← ← Take me back home!
How My Internet Bookmarks From 2005 Hold Up in 2021
I recently discovered a backed up copy of all my Firefox bookmarks from 2005. Seeing a bunch of old websites I used to frequent was certainly a nostalgia rush but I quickly realized that, predictably, many of the bookmarks no longer worked. In the name of science, I clicked through all 448 of them to see how bad the damage was:
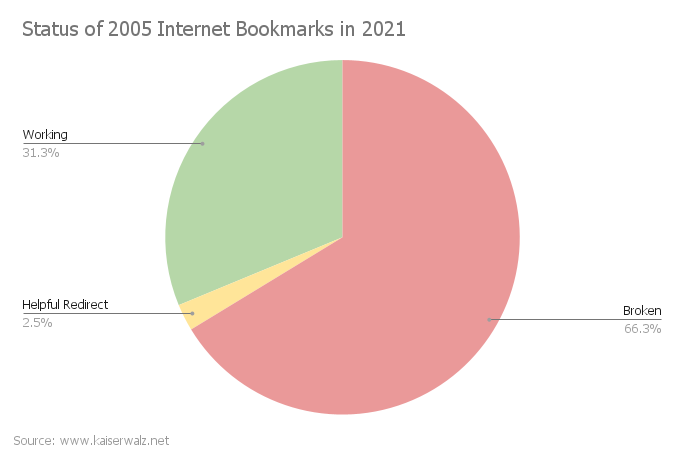
Not pretty.
A quick note on definitions here:
- I count a bookmark as working if a page loads and, as far as I can tell, contains the original content.
- Helpful Redirect means the original page is gone, but the owner has made a good faith attempt to redirect you to the content’s new location — more on this later.
- Broken is any other situation.
This is what’s known as link rot. URLs which used to point to something, no longer do. They’re referred to as dead links.
I was expecting that almost all of these old sites would simply no longer be online, but was surprised to find that many of the URLs still return something — just not the originally bookmarked content.
The Seven Types of Dead Links
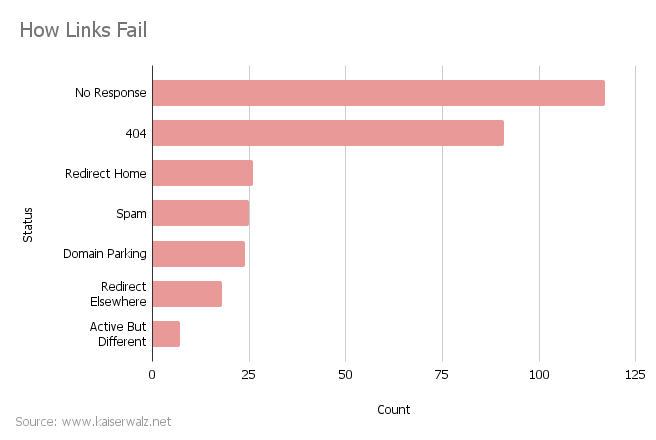
No Response
These links are truly dead. There is no longer any server at this address and you get your browser’s sad this site can’t be reached page:

404 (aka “page not found”)
A server is still living at this location, but the resource at the URL is no longer available.
Redirect Home
These links immediately redirect you to the site’s home page. Anecdotally, this strategy seems to be more common in larger commercial sites after they’ve gone through some kind of major overhaul.
It’s plausible that site owners prefer to use this type of redirect because they’re afraid showing a 404 message would drive people away, whereas presenting them with fresh content on the home page might entice users to stick around. Personally, I found this confusing and would recommend against doing this if you’re going to rework your site. If you don’t have the page the user is looking for, just fess up and show a 404.
Spam
The site is now used solely for the purpose of serving advertisements. This comes in two flavors:
- A page at the URL still exists, but all original content is gone and the new site is advertising some kind of unrelated product. These often take the form of spammy WordPress blogs.
- A redirect to some online store, totally unrelated to whatever the original page content was (e.g. a page on a video game site now redirects to a clothing merchant). A few theories as to what’s going on here:
- Spammers are buying up old sites and having all URLs at the domain send the user to a site as if they had clicked an advertisement, like a variation of click fraud.
- You are redirected to a merchant via an affiliate link, so that if you end up buying anything, the spammer get a payment.
- Shady SEO companies use these redirects to drive traffic to their customers, so as to make their SEO service seem more effective than it really is.
Domain Parking
Ownership of the domain name has lapsed and either reverted to the domain registrar or a reseller. The site now returns a domain parking page. These can be plain, but most are fairly spammy:

Ah, yes, this seems like a completely legitimate place to shop for a home loan.
Redirect Elsewhere
These links redirect you to a different site. The redirects tend to be generally helpful, with the domain owner trying to send you to either the original content’s new home, or at least something related. Some examples I saw:
- howstrange.com redirects to a Google Photos album containing many of the photoshop images the original site showcased
- lik-sang.com, a now defunct electronics store, redirects to the wikipedia page
- theknaves.com redirects to the band’s Facebook page
- exogenic.com redirects to the record label’s discogs page
Some (in)famous 00-era torrent sites, such as isoHunt and TorrentSpy now send you directly to an MPAA page with information about how to watch content legally.
Active But Different
This is kind of a catch-all category for the rare sites that are still fully online, but without the content you originally linked to. For example, a “this site is now shut down” type message:
- gliff.org has a farewell message, along with instructions

- The mozillaZine page “has gone into hibernation”
Some sites now just present a blank page. This is rare, but I saw a couple instances where the original domain is now used for a totally different purpose (for instance the site owner sold it to a different business, or decided to reuse the domain for some new project).
Conclusions
First of all, a disclaimer: these results are from a very un-random sampling and definitely should not be taken as representative of the larger internet.
But, based on the data I have, it’s actually more common for an old URL to serve a 404 or incorrect content than no content at all.
I was surprised at how many 404’s there were — around 30% of all dead links. I expected that most sites would either maintain their existing content or go offline completely, but it’s not uncommon for a site to continue running but lose its content over time. This is unfortunate, because it’s more preventable than the other types of issues.
You can’t really stop a business from folding or a hobby project from losing steam and eventually going offline. These things are inevitable. But, to the developers who are tasked with refactoring or modernizing their sites: I challenge you to try to maintain existing URLs where possible. This prevents dead links and helps keep the web healthy.
The Curious Amazon URL
One of my old bookmarks was this Amazon product page:
https://www.amazon.com/exec/obidos/tg/detail/-/0812966538
…and that URL still works, sixteen years later. No redirect, no 404, just straight up loads. The “obidos” in the URL refers to Amazon’s original page rendering engine, which was retired in 2006.
If you look up that same product today, it uses a totally different URL in the address bar:
https://www.amazon.com/Higher-Form-Killing-Chemical-Biological/dp/0812966538/
Amazon must have spent some effort making sure the old URLs would still work perfectly.
Fancy 404 Pages
There are really two types of 404 pages. First, the default webserver 404 error page:

The second type of 404 is a customized “sorry we couldn’t find this content” page. I’m calling these “fancy 404” pages:

This surprised me, but the fancy 404 page was more common than the default 404:
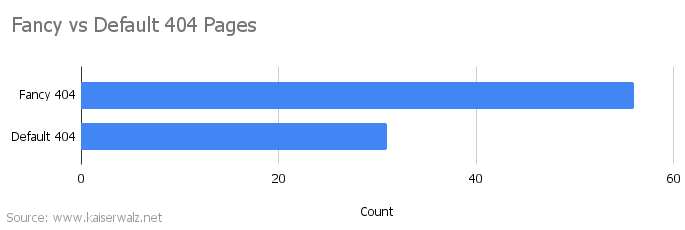
If I had to guess, fancy 404 pages are more common on large sites, which are more likely to still be standing after sixteen years. Perhaps smaller sites with no custom 404 page would be completely offline and in the “no response” category by now.
I’m Surprised These Are Still Online (as of time of writing)
A few of the pages that are still kickin after sixteen years…
- !Nerf Tech! - An Angelfire site about modifying Nerf guns
- RinkWorks
- Dvorak
- The Gauss Rifle: A Magnetic Linear Accelerator
- Film Sound Cliches
- This page about the famous Wilhelm Scream
- Creative Player Actions in FPS Online Video Games - Playing Counter-Strike
- Mignon Game Kit
- Some Half Life 2 mods:
- No More Room In Hell
- Dystopia
- Forsaken
Final Thought
More than anything, this little experiment illustrates a hard truth about the internet: it’s an ephemeral place, constantly shifting and changing, and anything you see out there might be gone tomorrow.
Thanks for reading! Published December 2021.
Wanna talk about it? You can contact me here